
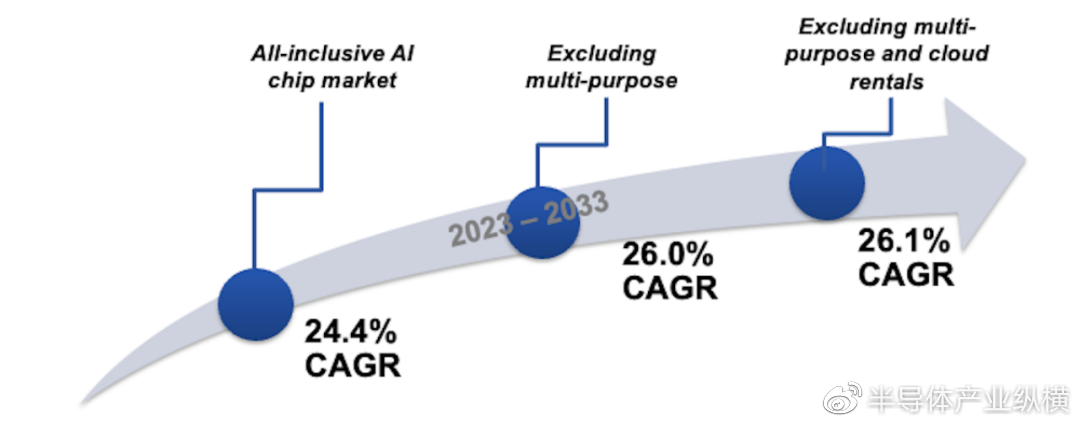
到 2033 年,全球 AI 芯片市场将增长到 2576 亿美元,届时最大的三个垂直行业是 IT 和电信、银行、金融服务和保险 (BFSI) 以及消费电子。人工智能正在改变我们所知的世界;从 2016 年 DeepMind over Go 世界冠军李世石的成功,到 OpenAI 的 ChatGPT 强大的预测能力,人工智能训练算法的复杂性正在以惊人的速度增长,其中运行新开发的训练算法所需的计算量似乎大约每四个月翻一番。为了跟上这种增长的步伐,人工智能应用程序需要的硬件不仅是可扩展的——允许随着新算法的引入而延长寿命,同时保持较低的运营开销——而且能够在接近最终用户的地方处理越来越复杂的模型。全面实现有效的物联网需要双管齐下的方法,即在云端和边缘处理人工智能。
经过专家分析师一段时间的专注研究,IDTechEx 发布了一份报告,对全球 AI 芯片技术格局和相应市场提供了独特的见解。包含与用于 AI 目的的 90 nm 至 3 nm 节点芯片的制造、设计、组装、测试和封装以及操作成本相关的严格计算。随着半导体制造商转向 3 nm以上的更先进节点,IDTechEx对设计成本和制造成本(每片晶圆的投资)进行了预测。
设计硬件来实现某种功能的概念,特别是如果该功能是通过将对它们的控制从主(主机)处理器上移开来加速某些类型的计算,这并不是一个新概念;计算的早期看到 CPU(中央处理单元)与数学协处理器配对,称为浮点单元 (FPU),其目的是将复杂的浮点数学运算从 CPU 卸载到这个专用芯片,因为后者可以以更有效的方式处理计算,从而释放 CPU 以专注于其他事情。随着市场和技术的发展,工作负载也在发展,因此需要新的硬件来处理这些工作负载。这些专门工作负载之一的一个特别值得注意的例子是GPU的制作。
正如计算机图形需要不同类型的芯片架构一样,机器学习的出现也带来了对另一种加速器的需求,一种能够有效处理机器学习工作负载的加速器。
人工智能硬件和软件的发展推动了全球的国家和地区资助计划。由于具有 AI 功能的处理器和加速器依赖于半导体制造商,这些制造商能够生产亚太地区数据中心内使用的芯片所需的更先进节点,因此制造 AI 芯片的能力取决于少数几家公司。
到 2020 年,许多因素(例如新冠疫情大流行、干旱、制造设施火灾爆发和稀有气体采购困难)导致全球芯片短缺,半导体芯片供不应求。从那时起,半导体价值链中最大的利益相关者(美国、欧盟、韩国、日本和中国)一直在寻求减少制造赤字的风险,以防万一出现导致平衡的另一组情况更加加剧了芯片短缺。国家和地区政府的举措已经到位,以激励半导体制造公司扩大业务或建设新设施。

机器学习是计算机程序利用数据根据模型进行预测,然后通过调整所用权重来优化模型以更好地适应所提供数据的过程。因此,计算涉及两个步骤:训练和推理。实施 AI 算法的第一个阶段是训练阶段,在此阶段,数据被输入模型,模型调整其权重,直到它与提供的数据适当匹配。第二阶段是推理阶段,执行经过训练的 AI 算法,并将新数据(在训练阶段未提供)以与获取的数据一致的方式进行分类。在这两个阶段中,训练阶段的计算量更大,鉴于此阶段涉及执行相同的计算数百万次(一些领先的 AI 算法的训练可能需要数天才能完成)。这就提出了一个问题:训练人工智能算法需要多少钱?
为了量化这一点,IDTechEx 严格计算了 AI 芯片从 90 nm到 3 nm的设计、制造、组装、测试和封装以及运营成本。通过考虑具有给定晶体管密度的 3 nm 芯片将比具有相同晶体管密度的更成熟的节点芯片具有更小的面积,可以将为给定 AI 算法部署前沿芯片的成本与落后,边缘芯片能够为相同的算法提供相似的性能。例如,基于我们使用的 3 nm 芯片模型,如果具有给定面积和晶体管密度的 3 nm芯片连续使用 5 年,所产生的成本将比具有相同晶体管密度的 90 nm芯片连续运行 5 年的成本低 45.4 倍。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系15950995158。
Copyright © 2022 深圳市杰和科技发展有限公司全资下属子公司东莞市杰拓通讯技术有限公司


